- 키-값 저장소 (key-value store)
- 비관계형(non-relational) 데이터베이스
- 이 저장소에 저장되는 값은 고유 식별자(identifier)를 키로 가져와야 함
- 키-값을 쌍(pair)이라 지칭
- 값(value)은 문자열, 리스트, object 등 무엇이 오든 상관하지 않음
- ex. 아마존 다이나모, memcached, redis 등
- 이번 장에서는 put, get 연산을 지원하는 키-값 저장소 설계
문제 이해 및 설계 범위 확정
- 키-값 쌍의 크기는 10KB 이하
- 큰 데이터를 저장할 수 있어야 함
- 높은 가용성 제공 → 장애가 있더라도 빨리 응답해야 함
- 높은 규모 확장성 제공 → 트래핑 양에 따라 자동적으로 서버 증설/삭제가 이루어져야 함
- 데이터 일관성 수준은 조정이 가능해야 함
- latency가 짧아야 함
단일 서버 키-값 저장소
- 가장 직관적인 방법
- 키-값 쌍 전부를 메모리에 해시 테이블로 저장
- 모든 데이터를 메모리 안에 두는 것이 불가능. 설령 디스크를 활용하더라도 서버 1대로 부족해질 수 있음
분산 서버 키-값 저장소
- 분산 해시 테이블
- 키-값 쌍을 여러 서버에 분산시킴
CAP 정리
- 분산 시스템 설계를 위해 필요한 정리
- 데이터 일관성 (Consistency)
- 분산 시스템에 접속하는 모든 클라이언트는 어떤 노드에 접속했느냐에 관계없이 언제나 같은 데이터를 보게 되어야 함
- 가용성 (Availability)
- 분산 시스템에 접속하는 클라이언트는 일부 노드에 장애가 발생하더라도 항상 응답을 받을 수 있어야 함
- 파티션 감내 (Partition tolerance)
- 파티션은 두 노드 사이에 통신 장애가 발생하였음을 의미함
- 네트워크 파티션이 생기더라도 시스템은 계속 동작하여야 함
세 가지 요구사항을 동시에 만족하는 분산 시스템을 설계하는 것은 불가능
- CP 시스템
- 일관성과 파티션 감내를 지원하는 키-값 저장소
- 가용성 희생
- AP 시스템
- 가용성과 파티션 감내를 지원하는 키-값 저장소
- 데이터 일관성 희생
- CA 시스템
- 일관성과 가용성을 지원하는 키-값 저장소
- 파티션 감내 지원하지 않음
- 그러나, 네트워크 장애는 피할 수 없는 일로 여겨지므로 파티션 문제는 반드시 감내할 수 있도록 설계되어야하기 때문에, CA 시스템은 존재하지 않음
이상적 형태
- 파티션되는 상황이 절대로 일어나지 않음
- n1에 기록된 데이터는 자동적으로 n2와 n3에 복제 (n 은 노드)
- 데이터 일관성과 가용성도 만족
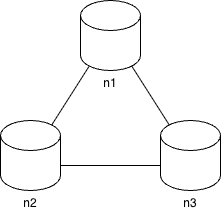
실세계의 분산 시스템
- 파티션 문제 발생 시, 일관성과 가용성 사이에서 하나 선택해야 함
- n3 장애 발생
- n1, n2에 기록된 데이터는 n3에 전달되지 않음
- n3에 기록되었으나 n1, n2로 전달되지 않은 데이터가 있다면, n1, n2가 가지고 있는 데이터는 오래된 데이터를 가지고 있음

- 일관성 선택 시(CP 시스템), 데이터 불일치 문제를 피하기 위해 n1, n2의 쓰기 연산 중단. 일반적으로 은행권 시스템에서 사용
- 가용성 선택 시(AP 시스템), 낡은 데이터를 반환할 위험이 있더라도 계속 읽기 연산 허용
시스템 컴포넌트
데이터 파티션
- 데이터 파티션을 나눌 때 중요하게 봐야할 부분
- 데이터를 여러 서버에 고르게 분산할 수 있는가
- 노드가 추가되거나 삭제될 때 데이터의 이동을 최소화할 수 있는가
- 안정해시(consistent hash) 가 적합
- 규모 확장 자동화(automatic scaling): 시스템 부하에 따라 서버가 자동으로 추가되거나 삭제되도록 만들 수 있음
- 다양성(heterogeneity): 각 서버의 용량에 맞게 가상노드의 수를 조정할 수 있음

데이터 다중화
- 높은 가용성과 안정성 확보를 위해 필요
- 어떤 키를 해시 링 위에 배치한 후, 그 지점으로부터 시계 방향으로 링을 순회하면서 만나는 첫 n개 서버에 데이터 사본 보관

- 실제 물리서버 개수는 n보다 작을 수 있으므로, 같은 물리서버를 중복 선택되지 않도록 해야함
- ex. 서버1: `s1, s4, s7` / 서버2: `s0, s2, s5` / 서버3: `s3, s6` → 서버 3대에 노드 7개 올라가 있는 예시
- 같은 데이터 센터에 속한 노드는 정전, 네트워크 이슈, 자연재해 등의 문제를 동시에 겪을 수 있으므로, 안정성 담보를 위해 데이터의 사본은 다른 센터의 서버에 보관하고, 센터들은 고속 네트워크로 연결해야 함
데이터 일관성
- 정족수의 합의(Quorum Consensus) 프로토콜 사용하여 읽기/쓰기 연산 모두에 일관성 보장할 수 있음
- 변수 정의
- N = 사본 개수
- W = 쓰기 연산에 대한 정족수. 쓰기 연산이 성공한 것으로 간주되려면 적어도 W개의 서버로부터 쓰기 연산이 성공했다는 응답을 받아야 함
- R = 읽기 연산에 대한 정족수. 읽기 연산이 성공한 것으로 간주되려면 적어도 R개의 서버로부터 읽기 연산이 성공했다는 응답을 받아야 함

- 중재자: 클라이언트와 노드 사이에서의 프록시(proxy) 역할을 함
- W, R, N 값을 정하는 것은 응답 지연과 데이터 일관성 사이의 타협점을 찾는 과정
- W = 1 일 경우, 최소 한 대의 서버로부터 쓰기 성공 응답을 받아야 함. 중재자가 s1 의 쓰기 연산 성공 응답을 받았다면, s0, s2 응답은 기다릴 필요 없음
- W = 1 or R = 1 일 경우, 응답 속도가 빠름
- W, R > 1 일 경우, 데이터 일관성 수준이 향상되지만 응답 지연 발생할 수 있음
- 구성 예시
- R = 1, W = N : 빠른 읽기 연산에 최적화된 시스템
- W = 1, R = N : 빠른 쓰기 연산에 최적화된 시스템
- W + R > N: 강한 일관성이 보장됨 (보통 N=3, W=R=2)
- W + R <= N: 강한 일관성이 보장되지 않음
일관성 모델
- 강한 일관성(strong consistency): 모든 읽기 연산은 가장 최근에 갱신된 결과를 반환. 클라이언트는 절대로 낡은(out-of-date) 데이터를 보지 못함
- → 모든 사본에 쓰기 연산 결과가 반영될 때까지 새로운 요청 처리가 중단되기 때문에, 고가용성에 적합하지 않음
- 약한 일관성(weak consistency): 읽기 연산은 가장 최근에 갱신된 결과를 반환하지 못할 수 있음
- 결과적 일관성(eventual consistency): 약한 일관성의 한 형태로, 갱신 결과가 결국에는 모든 사본에 반영되는 모델
- → Dynamo, Cassandra DB에서 채택하고 있음
- → 쓰기 연산이 병렬적으로 발생하기 때문에 일관성이 깨질 수 있는데, 이 문제는 클라이언트단에서 해결해야 함 → 해소 방법: 데이터 버저닝
비 일관성 해소 기법: 데이터 버저닝
- 버저닝(versioning) 과 벡터 시계(vector clock) 로 문제 해소 가능
- 버저닝: 데이터를 변경할 때마다 해당 데이터의 새로운 버전을 만드는 것을 의미. 각 버전의 데이터는 변경 불가능
- 데이터 일관성이 깨지는 예시

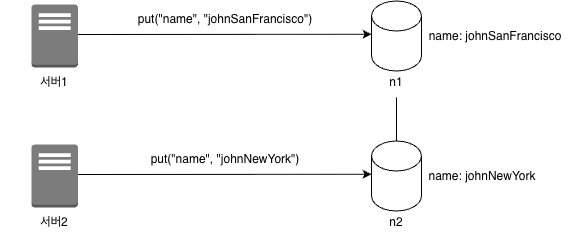
→ 보편적으로, 데이터 일관성 해결을 위해 벡터 시계를 활용하여 문제를 푼다고 함
- 벡터 시계: [서버, 버전] 순서쌍을 데이터에 매단 것
- 동일한 데이터에 대해 서버 별로 벡터시계 기록 (ex. D([서버 X, 3], [서버 Y, 1], [서버 Z, 1]))
- 버전 사이의 충돌 감지 방법
- D([서버0, 1], [서버1, 1]) 과 D([서버0, 1], [서버1, 2]) : 충돌이 아님. 후자가 더 상위버전
- D([서버0, 2], [서버1, 1]) 과 D([서버0, 1], [서버1, 2]) : 충돌
- 벡터 시계 사용하여 충돌을 감지하고 해소하는 방법의 단점
- 충돌 감지 및 해소 로직이 클라이언트에 들어가야 하므로, 클라이언트 구현이 복잡해짐
- [서버 : 버전] 의 순서쌍 개수가 굉장히 빨리 늘어남 → 임계치(threshold) 설정하여 오래된 순서쌍 제거하도록 하기(해당 방법은 아마존 실서비스에서 크게 문제된 적은 없었다고 함)
장애 처리
장애 감지 (failure detection)
- 일반적으로, 멀티캐스팅(multicasting) 채널을 구축하여, 서버 두 대 이상이 장애를 감지하면, 장애 발생했다고 간주 → 그러나, 서버가 많을 때 해당 방법은 비효율적
- 가십 프로토콜(gossip protocol) 같은 분산형 장애 감지(decentralized failure detection) 솔루션이 더 효율적
- (1) 각 노드는 멤버십 목록을 유지. 멤버십 목록은 각 멤버ID-heartbeat_counter 쌍의 목록임
- (2) 각 노드는 주기적으로 자신의 heartbeat_counter 를 증가시킴
- (3) 각 노드는 무작위로 선정된 노드들에게 주기적으로 자기 heartbeat_counter 목록을 보냄 (참고: 다른 자료 확인했을 때, push 시키는 것보다 pull 이 오버헤드가 작다고 함)
- (4) heartbeat_counter 목록을 받은 노드는 멤버십 목록을 최신 값으로 갱신
- (5) 어떤 멤버의 heartbeat_counter 값이 지정된 시간 동안 갱신되지 않으면, 해당 멤버는 장애(offline) 상태인 것으로 간주
일시적 장애 처리
- 엄격한 정족수(strict quorum) 접근법을 쓴다면, 장애 발생 시 읽기/쓰기 연산 금지
- 느슨한 정족수(sloppy quorum) 접근법은 연산을 수행할 N개의 서버를 해시링에서 골라 연산 수행 → 가용성을 높임
- 장애 서버로 가는 요청은 다른 서버가 잠시 맡아 처리하는데, 이 때 쓰기 연산을 처리한 서버에는 단서(hint) 를 남겨둠.(임시 위탁(hinted handoff) 기법) → 장애 서버 복구 시 일괄 반영하여 일관성 보존
영구 장애 처리
- 영구적인 노드 장애의 경우(~=데이터 불일치), 안티 엔트로피 프로토콜을 구현하여 사본 동기화
- 안티 엔트로피 프로토콜은 사본들을 비교하여 최신 버전으로 갱신하는 과정을 포함함
- 사본 간의 일관성이 망가진 상태를 탐지하고, 전송 데이터의 양을 줄이기 위해 머클(Merkle) 트리 사용
- 머클트리(해시트리): 각 노드의 종단 노드에 보관된 값의 해시, 혹은 종단 노드로부터 계산된 해시 값을 레이블로 붙여둔 트리
- 예시: 키 공간(key space)이 1부터 12까지일 경우, 머클 트리를 만드는 과정
- 1단계: 키 공간을 버킷(bucket)으로 나눔 (아래 그림에서는 버킷 4개로 나눔)

- 2단계: 버킷에 포함된 각각의 키에 균등 분포 해시(uniform hash) 함수를 적용하여 해시 값 계산

- 3단계: 버킷별로 해시값을 계산한 후, 해당 해시 값을 레이블로 갖는 노드를 만듦

- 4단계: 자식 노드의 레이블로부터 새로운 해시 값을 계산하여, 이진 트리를 상향식(bottom-up)으로 구성해나감

- 1단계: 키 공간을 버킷(bucket)으로 나눔 (아래 그림에서는 버킷 4개로 나눔)
- 위와 같이 루트 노드의 해시값을 비교하여, 다른 데이터를 갖는 버킷을 찾아 그 버킷만 동기화하면 됨
- 버킷 하나에 많은 데이터가 들어갈 수 있으므로, 버킷 하나의 데이터 크기는 꽤 크다는 것을 알아두어야 함. (ex. 전체 key 개수 10억개일 경우, 10만개의 버킷으로 관리하며, 버킷 당 key 1000개씩 관리)
데이터 센터 장애 처리
- 데이터 센터 장애에 대응을 위해 데이터를 여러 데이터 센터에 다중화
시스템 아키텍처 다이어그램
주된 기능 설명
- 클라이언트는 키-값 저장소가 제공하는 두 가지 단순한 API(get, put)와 통신
- 중재자는 클라이언트에게 키-값 저장소에 대한 proxy 역할을 하는 노드
- 노드는 안정 해시(consistent hash) 의 해시 링(hash ring) 위에 분포
- 노드를 자동으로 추가 또는 삭제할 수 있도록, 시스템은 완전히 분산되어야 함
- 데이터는 여러 노드에 다중화
- 모든 노드가 같은 책임을 지므로, SPOF(Single Point of Failure)는 존재하지 않는다
- 모든 노드들은 앞서 이야기했던 장애 감지, 데이터 불일치 해소, 다중화 등의 모든 기능들이 전부 지원되어야 함
쓰기 경로

- 쓰기 요청이 커밋 로그(commit log) 파일에 기록됨
- 데이터가 메모리 캐시에 기록됨
- 메모리 캐시가 가득차거나 사전에 정의된 어떤 임계치에 도달하면 데이터는 디스크에 있는 SSTable에 기록됨SSTable: Sorted-String Table, <키, 값> 순서쌍을 정렬된 리스트 형태로 관리하는 테이블
읽기 경로
- SSTable에 데이터가 있는지 없는지를 조회하기 위해, 주로 블룸 필터(bloom filter) 를 사용
- 블룸 필터: boolean 형태의 테이블로, 값의 존재여부를 검사할 수 있는 데이터 구조
- 정확하게 "없다"를 말할 수는 있지만, 정확하게 "있다"를 말할 수는 없음 (해시 충돌 발생으로 인해 있다고 판단될 수 있기 때문에)

- 데이터가 메모리에 있는지 검사. 없다면 2번으로
- 데이터가 메모리에 없으므로 블룸 필터(bloom filter)를 검사
- 블룸 필터를 통해 어떤 SSTable에 키가 보관되어 있는지 알아냄
- SSTable에서 데이터를 가져옴
- 해당 데이터를 클라이언트에 반환
출처: 가상 면접 사례로 배우는 대규모 시스템 설계 기초(알렉스 쉬 저자, 이병준 번역)
'도서 > 대규모시스템설계기초1' 카테고리의 다른 글
| [가상 면접 사례로 배우는 대규모 시스템 설계 기초] 12장. 채팅 시스템 설계 (0) | 2025.11.03 |
|---|